

In the realm of computing, the terms FP16 and FP32 refer to floating-point formats used to represent numbers with fractional parts.
FP16 is not supported on the CPU, resulting in a User Warning. Instead, FP32 is used on CPUs. This limitation affects computations needing FP16 precision on CPU platforms.
In this article, we will explore the” FP16 Is Not Supported On CPU Using FP32 Instead.”
What is FP16?
FP16, or half-precision, is a format used to represent numbers with fractional parts using 16 bits. It offers faster computation and reduced memory usage but sacrifices some accuracy compared to higher precision formats like FP32.
What is FP32?

FP32, or single precision, is a format used to represent numbers with fractional parts using 32 bits. It provides higher accuracy and a wider range of representable numbers compared to FP16, making it suitable for tasks requiring precise calculations.
Improving Performance with FP16 on CPU
Improving performance with FP16 on a CPU can be tricky due to technical stuff. CPUs like things precise, so they use FP32 instead of FP16.
FP16 needs less memory and works faster, but CPUs prefer accuracy. Using FP32 on CPUs makes things simpler, but it can slow things down a bit. Researchers are looking for ways to make FP16 work better on CPUs.
Read: Fatal Glibc Error: CPU Does Not Support X86-64-V2 – Guide!
1. Why is FP16 Not Supported on CPUs?
FP16 is only used on CPUs a little because CPUs need higher precision for many jobs. FP16 uses fewer bits to store numbers, which means less accuracy. CPUs do many different tasks, so they need to be accurate. Using FP16 would require big changes in how CPUs work.
2. Achieving Improved Performance on CPUs
While CPUs don’t naturally support FP16, there are other ways to boost performance on CPUs:
A. Mixed Precision Training
Mixed precision training is a way to use both FP16 and FP32 together. Some parts of a task need high accuracy, so they use FP32. Other parts can use FP16 because they don’t need as much accuracy. This can make tasks faster without losing too much accuracy.
B. Quantization
Quantization is another way to use less precision. It means rounding numbers to fewer digits. This can result in faster calculations. But it can also make results less accurate. Finding the right balance is important for getting good results.
C. Parallelization
Parallelization means doing many tasks at the same time. CPUs have many cores that can work together. This can make tasks faster, but it can be challenging. Some tasks can’t be split into smaller parts easily. But for tasks that can, parallelization can make a big difference in speed.
What is the difference between FP16 and FP32?
FP16 and FP32 are different ways to store numbers. FP16 uses fewer bits than FP32, which means it can’t store numbers as precisely. FP32 is more accurate because it uses more bits.
Read: Docker Incompatible CPU Detected: Check Compatibility – 2024
The role of hardware accelerators
1. GPUs vs. CPUs
GPUs are super calculators, great for lots of math at once, with many tiny processors. CPUs are all-around helpers, not as good at lots of math, but versatile for many tasks.
2. Compatibility issues
When software and hardware don’t mesh well, it’s called compatibility issues. For instance, software may require specific hardware to run smoothly. If they’re not compatible, users and developers face problems.
Why is FP16 faster than FP32?
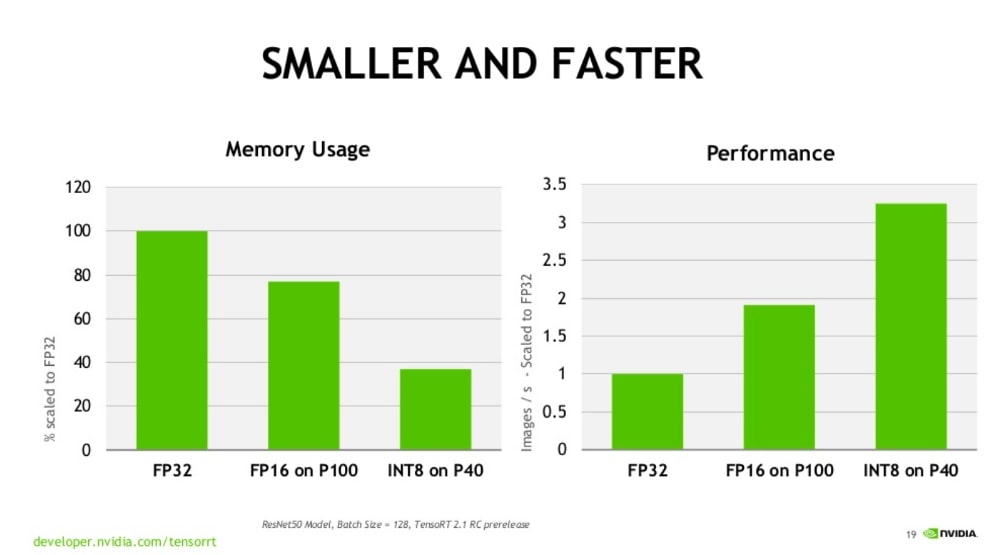
FP16 is faster than FP32 because it uses fewer bits to represent numbers. This means it takes less time for the CPU to process calculations with FP16 compared to FP32. However, FP16 sacrifices some accuracy for speed.
Whisper AI error : FP16 is not supported on CPU; using FP32 instead
When Whisper AI encounters FP16 data on a CPU, it can’t handle it because CPUs don’t support FP16 well. So, it switches to using FP32 instead. This might slow down processing but ensures compatibility.
Read: CPU Speed 1.1 GHz – Exploring Its Impact On Performance!
How can I switch from FP16 to FP32 in the code to avoid the warning?
To avoid the warning, you can modify your code to use FP32 instead of FP16. This ensures compatibility with CPUs that don’t support FP16 well. However, be aware that using FP32 might affect performance.
Openai whisper GPU requirements
OpenAI’s Whisper AI requires a GPU to run efficiently. GPUs are better at handling FP16 data compared to CPUs. So, if you want to use Whisper AI without encountering FP16 errors, make sure your system has a compatible GPU.
Whisper AI error : FP16 is not supported on CPU; using FP32 instead
When Whisper AI detects FP16 data on a CPU, it switches to using FP32 to avoid compatibility issues. This ensures that the AI can continue processing without errors, even though it might affect performance.
What is the difference between FP16 and FP32 when doing deep learning?
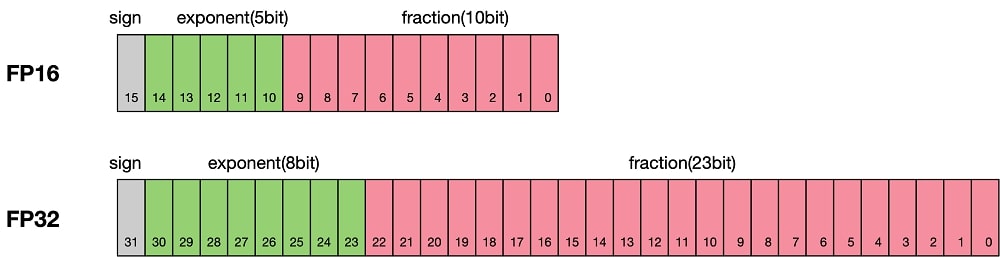
When doing deep learning, the difference between FP16 and FP32 lies in the precision of numbers they can represent.
FP16 uses fewer bits than FP32, which means it can’t represent numbers precisely. This can affect the accuracy of deep learning models.
What does FP32 mean in deep learning?
In deep learning, FP32 refers to 32-bit floating-point precision, which is a standard format used to represent numbers with fractional parts.
FP32 provides higher precision compared to FP16, allowing for more accurate calculations in deep learning models.
Read: Pfsense CPU Doesn’t Support Long Mode – Solutions In 2024!
FAQs
1. Can I manually use FP16 on a CPU?
Manually using FP16 on a CPU is difficult as CPUs lack native support for it, requiring extensive modifications to software and hardware.
2. Are there any alternatives to FP16 for improving CPU performance?
Alternatives to FP16 for enhancing CPU performance include mixed precision training, quantization, and parallelization techniques, which optimize computational efficiency.
3. Can GPUs handle FP16 and FP32 simultaneously?
GPUs can handle both FP16 and FP32 simultaneously, allowing for mixed precision computations, but compatibility issues may arise on some systems.
4. ValueError: Mixed precision training with AMP or APEX (`–fp16`) and FP16 evaluation can only be used on CUDA devices
This error indicates that mixed precision training with AMP or APEX and FP16 evaluation is only supported on CUDA devices, not on CPUs.
5. Whisper fp16 is not supported on CPU using fp32 instead.
Whisper AI switches to using FP32 instead of FP16 on CPUs due to lack of support, ensuring compatibility but potentially affecting performance.
6. What is the range of FP32 vs FP16?
FP32 has a wider range and higher precision compared to FP16, allowing it to represent larger numbers and provide more accurate results.
7. Is BF16 better than FP16?
BF16, or Brain Floating-Point 16, offers benefits over FP16 in certain applications due to improved precision and compatibility with existing hardware and software.
8. Does P100 support FP16?
Yes, the P100 GPU supports FP16, providing improved performance for certain tasks compared to FP32.
9. Are there any benefits to using FP32 on CPU?
Using FP32 on CPUs ensures compatibility and stability across different hardware platforms and simplifies software development but may result in suboptimal performance in certain scenarios.
10. Will there be support for FP16 on CPUs in the future?
Future developments in hardware and software technology could lead to better support for FP16 on CPUs or alternative solutions that offer comparable performance with higher efficiency.
Conclusion
In conclusion, FP16 is not natively supported on CPUs, leading to the use of FP32 instead. While this limits performance for tasks needing FP16 precision, alternative methods like mixed precision training and quantization offer avenues for enhancing CPU performance in the future.
Read More
- Cannot Pin ‘Torch.Cuda.Longtensor’ Only Dense CPU Tensors Can Be Pinned
- Process Lasso Error Setting Process CPU Affinity – Resolve!
- Is Tarkov Cpu Or Gpu Intensive – A Complete Tips In 2024!

Hi everyone, Johns Jack here, your approachable tech aficionado! I’m passionate about CPUs and thrive on keeping up with the newest tech developments. Join me as we delve into the dynamic realm of technology! Visit: Techy Impacts