

In the realm of machine learning, the efficient handling of tensors plays a pivotal role in achieving optimal performance.
Error: “Cannot pin ‘torch.cuda.longtensor’ – only dense CPU tensors can be pinned.” Solution: Use dense CPU tensors for pinning, as pinning GPU tensors like ‘torch.cuda.longtensor’ is not supported.
In this article, we will delve into the intricacies of tensor operations, explore the reasons behind the inability to pin ‘torch.cuda.longtensor,’ and provide insights into potential solutions and workarounds.
Understanding ‘torch.cuda.longtensor’ and Dense CPU Tensors
Let’s distinguish between ‘torch.cuda.longtensor’ and dense CPU tensors in PyTorch. It’s like comparing Four scenarios of ingredients for cooking: each has its unique qualities and uses.
Scenario 1: Pinning ‘torch.cuda.longtensor’ to CPU Memory
Imagine you have a special tool (‘torch.cuda.longtensor’) that you want to use in a different kitchen (‘CPU memory’). Pinning it is like ensuring it stays handy so you can grab it quickly whenever needed.
Scenario 2: Converting ‘torch.cuda.longtensor’ to Dense CPU Tensor
Now, if you want to use that special tool (‘torch.cuda.longtensor’) in another kitchen (‘dense CPU tensor’), you might need to tweak it a bit, like changing the handle or adjusting its size, so it fits and works smoothly.
Scenario 3: Utilizing GPU Memory Efficiently
Think of GPU memory as a toolbox for a specific task. Using it efficiently means organizing your tools neatly, knowing which ones you need for the job, and ensuring they’re easily accessible so you can work faster and with fewer interruptions.
Scenario 4: Updating PyTorch Versions
Just like updating your favourite app on your phone, keeping PyTorch up to date means getting the latest features, improvements, and bug fixes. It’s like getting fresh ingredients for your recipes, making your cooking experience even better.
Read Also: CPU Tweaker Windows 10 64 Bit – A Complete Overview – 2024!
What is ‘torch.cuda.longtensor’?

1. Definition and Purpose
‘Torch.cuda.longtensor’ refers to tensors specifically designed for GPU operations, particularly for handling long integer data types.
These tensors are optimized for parallel processing on GPUs, aiming to expedite numerical computations in machine learning tasks.
2. Differences Between Dense CPU Tensors and GPU Tensors
Dense CPU tensors and GPU tensors have distinct characteristics. While CPU tensors are suitable for certain tasks, GPU tensors offer significant advantages in parallel processing.
The inability to pin ‘torch.cuda.longtensor’ raises questions about the nuances of pinning GPU tensors.
What are dense CPU Tensor?
Dense tensors store values in a contiguous sequential block of memory, where all values are represented. Tensors, or multi-dimensional arrays, are utilized in a wide range of multi-dimensional data analysis applications.
Various software products are available for performing tensor computations, including the MATLAB suite, which has been supplemented by various open-source third-party toolboxes.
MATLAB alone can support a variety of element-wise and binary dense tensor operations. A dense layer, also known as a fully connected layer, ensures that each neuron receives input from all neurons in the previous layer, resulting in dense connectivity.
Consequently, every neuron in a dense layer is fully connected to every neuron in the preceding layer.
Read Also: What CPU Will Bottleneck A Rtx 3060 – Check Bottleneck Risk!
Pinning in PyTorch

1. Understanding Tensor Pinning
Tensor pinning involves allocating a fixed memory location for a tensor, preventing the system from moving during operations. This is particularly useful in scenarios where data needs to be shared efficiently between CPU and GPU.
2. Why ‘torch.cuda.longtensor’ Cannot Be Pinned
The error message “cannot pin ‘torch.cuda.longtensor’ – only dense CPU tensors can be pinned” indicates a limitation in the current implementation of PyTorch.
Pinning GPU tensors introduces complexities due to the differences in memory management between CPU and GPU.
Peculiarities of CPU and GPU Tensors
1. Exploring Dense CPU Tensors
Dense CPU tensors, unlike their GPU counterparts, do not face the same constraints regarding pinning. Understanding the characteristics of dense CPU tensors provides context to the limitations posed by GPU tensors.
2. Limitations of Pinning GPU Tensors
GPU tensors, including ‘torch.cuda.longtensor,’ present challenges in memory management, making it difficult to pin them. This limitation stems from the intricate architecture of GPUs and the need for efficient parallel processing.
3. Implications for Machine Learning Tasks
In the context of machine learning, where data movement efficiency is paramount, the inability to pin ‘torch.cuda.longtensor’ can impact certain tasks. It is crucial to consider these implications when designing and optimizing deep learning models.
Read Also: Bad CPU Type In Executable Homebrew – Ultimate Guide In 2024
Common Errors and Debugging
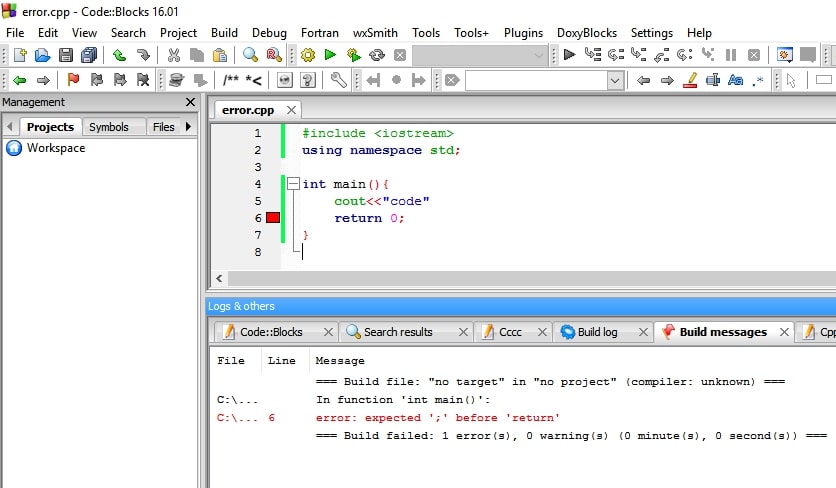
- Addressing the Error Message
When encountering the error message related to pinning ‘torch.cuda.longtensor,’ it is essential to understand the context in which it occurs. Examining the code and identifying potential alternatives or workarounds can aid in resolving the issue.
- Troubleshooting Steps for ‘torch.cuda.longtensor’ Issue
Debugging in PyTorch involves systematic steps, including checking the compatibility of the code with GPU tensors, verifying the memory requirements, and exploring community forums for insights. Taking a methodical approach can often lead to effective solutions.
Read Also: Rcu_sched Self-Detected Stall On CPU – Know The Truth – 2024
Alternatives and Workarounds
1. Using CPU Tensors for Pinning
One viable solution to the ‘torch.cuda.longtensor’ issue is to use dense CPU tensors for pinning. While this may introduce a slight performance trade-off, it ensures compatibility with the current limitations in GPU tensor pinning.
2. Modifying the Code to Accommodate GPU Constraints
Adapting the code to work seamlessly with GPU constraints is another approach. This may involve restructuring the tensor operations or exploring alternative data types that align better with GPU memory management.
Best Practices in Tensor Handling

1. Optimizing Tensor Operations for Performance
To mitigate the impact of the ‘torch.cuda.longtensor’ limitation, adopting best practices in tensor handling becomes crucial.
This includes optimizing tensor operations for performance and considering the specific requirements of GPU acceleration.
2. Ensuring Compatibility Across Different Hardware Configurations
As machine learning models are deployed on various hardware configurations, ensuring compatibility becomes paramount.
Developing models that can seamlessly adapt to different environments minimizes potential issues related to tensor operations.
Read Also: CPU Machine Check Architecture Error Dump – Solution In 2024
How to Troubleshoot and Fix the Issue
- Check Hardware Compatibility: Ensure that your hardware configuration supports GPU acceleration and that CUDA is correctly installed on your system.
- Verify CUDA Installation: Double-check that CUDA is correctly installed and configured with PyTorch. Any mismatch or incomplete installation can lead to compatibility issues and errors.
- Ensure Proper Tensor Initialization: Ensure that tensors are correctly initialized and that there are no inconsistencies in tensor types or device assignments.
- Avoid Mixing CPU and GPU Tensors: Steer clear of mixing CPU and GPU tensors in operations that involve pinning. Stick to homogeneous tensor types to prevent compatibility issues.
- Optimize Tensor Operations for GPU Usage: Make the most of GPU acceleration by optimizing your tensor operations. Utilize PyTorch’s built-in functions and GPU-specific optimizations whenever possible.
Real-world Applications
- Instances Where Tensor Pinning is Crucial
In certain machine learning tasks, tensor pinning is crucial for efficient data sharing between CPU and GPU. Identifying scenarios where pinning is essential helps in designing robust and versatile models.
- How Avoiding ‘torch.cuda.longtensor’ Can Impact Machine Learning Models
By understanding the limitations of ‘torch.cuda.longtensor’ and avoiding its use in scenarios where pinning is necessary, machine learning practitioners can make informed decisions to prevent potential performance bottlenecks.
Community Discussions and Solutions

- Exploring Forums and Community Threads
Community discussions provide valuable insights into common issues and solutions. Exploring forums dedicated to PyTorch and CUDA can offer a wealth of knowledge from experienced practitioners who have encountered and addressed similar challenges.
- Learning From Shared Experiences and Solutions
Learning from shared experiences and solutions in the community can expedite the troubleshooting process. Leveraging the collective knowledge of the community ensures a collaborative approach to overcoming challenges in tensor handling.
Read Also: Is CPU Z Safe – Explore The Safety Of CPU Z In 2024!
Future Developments
1. Updates on PyTorch and CUDA Compatibility
The field of deep learning is dynamic, with continuous advancements in frameworks and hardware. Keeping abreast of updates related to PyTorch and CUDA compatibility is essential for staying informed about potential resolutions for the ‘torch.cuda.longtensor’ issue.
2. Potential Resolutions for the ‘torch.cuda.longtensor’ Issue
As the PyTorch community actively addresses issues and introduces updates, potential resolutions for the ‘torch.cuda.longtensor’ limitation may emerge. Staying engaged with the community and being open to adopting new practices is key to staying ahead.
Pytorch. How Does pin_memory work In Dataloader?
Host to GPU copies are faster when using pinned (page-locked) memory. Enabling pin_memory=True in a DataLoader speeds up data transfer to CUDA-enabled GPUs by automatically putting fetched data Tensors into pinned memory.
By default, only recognized Tensors and mapped iterables are pinned. To pin custom batch types or data, define a pin_memory() method on the custom type(s).
Using Trainer with LayoutXLM for classification
Using Trainer with LayoutXLM for classification involves training a model to categorize data using LayoutXLM architecture, enhancing classification accuracy and performance in multilingual document processing tasks.
Pin_memory报错解决:runtimeerror: Cannot Pin ‘cudacomplexfloattype‘ Only Dense Cpu Tensors Can Be Pinned
To resolve the Pin_memory error “RuntimeError: Cannot Pin ‘CudaComplexFloatType’ Only Dense CPU Tensors Can Be Pinned,” consider converting CUDA complex float tensors to dense CPU tensors.
Read Also: CPU Maximum Frequency Always 100 – Ultimate Guide – 2024!
Runtimeerror: Pin Memory Thread Exited Unexpectedly
The “RuntimeError: Pin Memory Thread Exited Unexpectedly” occurs when a pin memory thread unexpectedly terminates during execution. Troubleshoot by checking memory allocation and system resources.
Pytorch Not Using All GPU Memory
If PyTorch is not utilizing all available GPU memory, it could be due to insufficient data to fill the memory, memory fragmentation, or limitations imposed by PyTorch’s memory management.
Huggingface Trainer Use Only One Gpu
When Hugging Face Trainer utilizes only one GPU, it may be due to its default configuration or GPU availability settings. Check the trainer configuration and ensure proper GPU allocation for training.
Error during fit the model #2
There’s a problem fitting the model, marked as “#2”. This means there’s an issue with the second attempt to train the model. It could be due to data errors, code bugs, or model configuration problems.
RuntimeError: cannot pin ‘torch.cuda.DoubleTensor’ on GPU on version 0.10.0 #164
A technical issue called “RuntimeError” says it can’t pin a specific type of tensor on the GPU. This occurred in version 0.10.0 and involved a tensor type called “torch.cuda.DoubleTensor”. It suggests a problem with memory management on the GPU during runtime.
Should I turn off `pin_memory` when I already loaded the image to the GPU in `__getitem__`?
Yes, you should turn off `pin_memory` when you’ve already loaded the image onto the GPU in `__getitem__`. `pin_memory` is mainly used for speeding up data transfer between CPU and GPU. Still, if your data is already on the GPU, it’s unnecessary and can cause issues.
The speedups for TorchDynamo mostly come with GPU Ampere or higher and which is not detected here
The performance boosts for TorchDynamo are primarily seen with GPU models like Ampere or newer, which aren’t recognized in this case. The system may not have the compatible hardware required to leverage the full potential of TorchDynamo’s optimizations.
GPU utilization 0 pytorch
The GPU utilization is at 0 in PyTorch. This indicates that the GPU is not currently being utilized for any computations by PyTorch. It could be due to various reasons, such as lack of GPU support, insufficient memory, or improper configuration.
When to set pin_memory to true?
Set `pin_memory` to true when loading data with DataLoader if you’re using CUDA, as it helps speed up data transfers between CPU and GPU, enhancing performance.
Pytorch pin_memory out of memory
If you encounter an “out of memory” error in PyTorch with `pin_memory`, it suggests that the system’s GPU memory is insufficient to handle the data transfer operations.
Can’t send PyTorch tensor to Cuda
If you can’t send a PyTorch tensor to CUDA, it likely means there’s an issue with GPU availability or compatibility. Check if CUDA is properly installed and if your system supports GPU acceleration.
Differences between `torch.Tensor` and `torch.cuda.Tensor`
The main difference between `torch.Tensor` and `torch.cuda.Tensor` lies in where they are stored: `torch.Tensor` resides in CPU memory, while `torch.cuda.Tensor` resides in GPU memory. The latter is specifically designed for computations on the GPU, offering faster processing for deep learning tasks.
Torch.Tensor — PyTorch 2.3 documentation
The “Torch.Tensor — PyTorch 2.3” documentation likely provides information about the `torch.Tensor` class in PyTorch version 2.3. It likely covers various methods, attributes, and usage instructions for working with tensors in PyTorch version 2.3.
Optimize PyTorch Performance for Speed and Memory Efficiency (2022)
Enhance PyTorch performance by optimizing for speed and memory efficiency, ensuring faster computations and optimal resource utilization, beneficial for deep learning tasks in 2022.
RuntimeError Caught RuntimeError in pin memory thread for device 0
The error message “RuntimeError Caught RuntimeError in pin memory thread for device 0” indicates an issue occurred while attempting to pin memory for a device (likely a GPU) during runtime.
Read Also: Is 80c Safe For CPU – Check CPU Temperature For Safety!
In A Nutshell
Addressing the ‘torch.cuda.longtensor’ pinning issue requires a shift to dense CPU tensors for optimal performance.
Exploring alternatives, understanding GPU limitations, and engaging with the community for shared experiences are crucial steps.
Staying informed about PyTorch updates and potential resolutions ensures adaptability in the dynamic field of deep learning.
Related Questions
1. What is Tensor Pinning in PyTorch?
Tensor pinning in PyTorch involves allocating a fixed memory location for a tensor, preventing the system from moving it during operations. This is particularly useful for efficient data sharing between CPU and GPU.
2. Can I Use ‘torch.cuda.longtensor’ in CPU-only Mode?
No, ‘torch.cuda.longtensor’ is specifically designed for GPU operations. Attempting to use it in CPU-only mode will result in an error.
3. Are There Other Similar Tensor-Related Issues in PyTorch?
Yes, PyTorch, like any complex framework, may have other tensor-related issues. It is recommended to explore community forums and documentation for solutions to specific problems.
4. How Does Tensor Handling Impact Machine Learning Performance?
Efficient tensor handling is crucial for optimal machine learning performance. Suboptimal tensor operations can lead to performance bottlenecks, especially in large-scale deep-learning tasks.
5. Where Can I Find More Resources on PyTorch Debugging?
For additional resources on PyTorch debugging, community forums, official documentation, and online tutorials are valuable sources. Engaging with the community and learning from shared experiences can enhance your debugging skills.
6. What does Pin_memory do in Pytorch?
Setting pin_memory = True is utilized to allocate memory on RAM, facilitating faster data transfer between RAM and GPU/CPU. The allocated GPU RAM will persist until the completion of training. This is because resources are specifically allocated for the training process.
7. Training error when pin_memory=True and collate_fn passes sparse tensors to the batch?
When pin_memory=True and collate_fn passes sparse tensors to the batch, it can lead to training errors.
8. Cannot pin ‘torch.cuda.floattensor’ only dense cpu tensors can be pinned?
When attempting to pin ‘torch.cuda.floattensor’, you’ll encounter an error as only dense CPU tensors can be pinned. This limitation arises due to differences in memory management between CPU and GPU, making pinning unsupported for GPU tensors.
Also Read
- Fatal Glibc Error: CPU Does Not Support X86-64-V2 – Guide!
- What Is VDDCR CPU Voltage? – Optimize CPU Voltage Settings!
- Pre Memory CPU Initialization Is Started – Steps By Steps!

Hi everyone, Johns Jack here, your approachable tech aficionado! I’m passionate about CPUs and thrive on keeping up with the newest tech developments. Join me as we delve into the dynamic realm of technology! Visit: Techy Impacts