

In the intricate ecosystem of the Linux kernel, Read-Copy Update (RCU) stands as a fundamental mechanism facilitating concurrency without the need for locks.
“Rcu_sched Self-Detected Stall On CPU” refers to a situation where the RCU scheduler detects a stall on the CPU, causing unresponsiveness. It can lead to ‘soft lockup’ errors and hinder device accessibility via SSH.
In this article, we will explore “Rcu_sched Self-Detected Stall On CPU”
Understanding CPU Stalls
CPU stalls happen when your computer’s brain, the CPU, can’t do what it’s supposed to do. It’s like a traffic jam on your computer!
The CPU gets stuck because it’s waiting for something to happen, like waiting for data or sharing resources with other parts.
This can slow down your computer and make it less responsive. Imagine being stuck in traffic – frustrating, right? That’s how your CPU feels during a stall!
What Is Rcu_sched Self-Detected Stall?
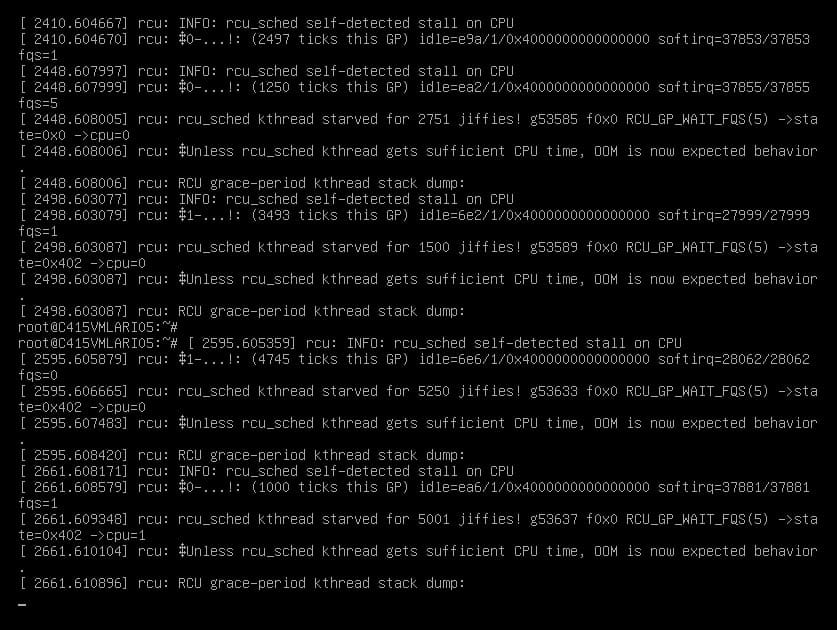
RCU_sched self-detected stall is like when your computer’s traffic controller notices a big jam in its traffic flow.
It happens when the part of your computer that manages shared information, RCU_sched, realizes it can’t keep things moving smoothly.
This could be because it’s waiting too long for something, or there needs to be more going on at once.
Just like when you’re waiting for something important, your computer gets stuck, slowing everything down.
Causes Of Rcu_sched Self-Detected Stall
There are several reasons why RCU_sched self-detected stalls can happen:
- High CPU Load: When your computer works too hard, it can overwhelm the RCU scheduler, causing it to slow down.
- Too Many Requests: If too many are needed for attention at once, the RCU scheduler can struggle to source Contention easily. When different parts of your computer are fighting over the same resources, like memory or processing power, it can cause delays in RCU scheduling.
- Lock Contention: Sometimes, multiple tasks need to access the same data simultaneously, leading to conflicts and delays in the RCU scheduler’s operations.
- Synchronization Overheads: Managing synchronization between different system parts can introduce delays in RCU scheduling, especially if it needs to be done more efficiently.
- Hardware Limitations: Older or less powerful hardware may need help to keep up with the demands placed on the RCU scheduler, leading to stalls.
- Software Bugs: Errors in the software code can also cause RCU_sched self-detected stalls, especially if they’re related to how tasks are scheduled and managed by the RCU scheduler.
Read: Does AMD GPU Work With Intel CPU – Explore Compatibility!
Impact Of Rcu_sched Self-Detected Stall
When an RCU_sched self-detected stall occurs, it can have significant impacts on your computer’s performance:
- Decreased Responsiveness: Your computer may need to be faster to respond to your commands or take longer to complete tasks.
- Reduced Throughput: The overall efficiency of your system may decrease, leading to slower processing speeds and decreased productivity.
- Increased Latency: Tasks that require immediate attention may experience delays, causing increased latency and frustration for users.
- System Instability: RCU_sched self-detected stalls can sometimes lead to system crashes or instability, requiring you to restart your computer to resolve the issue.
- User Frustration: Constant stalls and slowdowns can frustrate users and negatively impact their experience, leading to dissatisfaction with the system’s performance.
Detecting Rcu_sched Self-Detected Stall

Detecting RCU_sched self-detected stalls requires monitoring and analysis of system metrics, including:
CPU Utilization
CPU utilization shows how much of the computer’s brainpower is being used. If it’s too high like when many programs run simultaneously, it can slow down tasks and make your computer sluggish.
Lock Contention Metrics
Lock contention metrics measure resource conflicts in your computer. High Contention indicates intense competition for resources, causing delays.
Monitoring these metrics helps identify and address performance issues efficiently.
RCU Tracing
RCU tracing is a method of tracking the behavior of the Read-Copy Update (RCU) mechanism in the Linux kernel.
By enabling RCU tracing, developers can gain insights into how RCU operations are executed and identify potential issues or bottlenecks in the system.
This tracing helps debug and optimize RCU implementations for better performance and scalability.
Read: Why Is My CPU Not Being Utilized – Troubleshoot CPU Issues!
How To Troubleshoot Rcu_sched Self-Detected Stall
When facing an RCU_sched self-detected stall, here are seven troubleshooting steps to consider:
- Monitor System Health: Monitor CPU utilization and lock contention metrics to identify high load or resource conflict periods.
- Analyze System Logs: Review system logs and kernel messages for any indications of RCU_sched self-detected stalls or related issues.
- Use Performance Profiling Tools: Utilize performance profiling tools to pinpoint areas of code that may be causing stalls and optimize them for better performance.
- Identify Bottlenecks: Look for performance bottlenecks such as high CPU load or excessive synchronization overheads contributing to stall conditions.
- Check Hardware Limitations: Ensure that hardware limitations are not hindering the performance of the RCU scheduler, especially on older or less powerful systems.
- Optimize Locking Strategies: Fine-tune locking strategies to minimize Contention and reduce synchronization overheads, improving the efficiency of the RCU scheduler.
- Adjust RCU Parameters: Experiment with adjusting RCU parameters such as grace periods and batch sizes to optimize the behavior of the RCU scheduler and reduce stall conditions.
Addressing Rcu_Sched Stalls
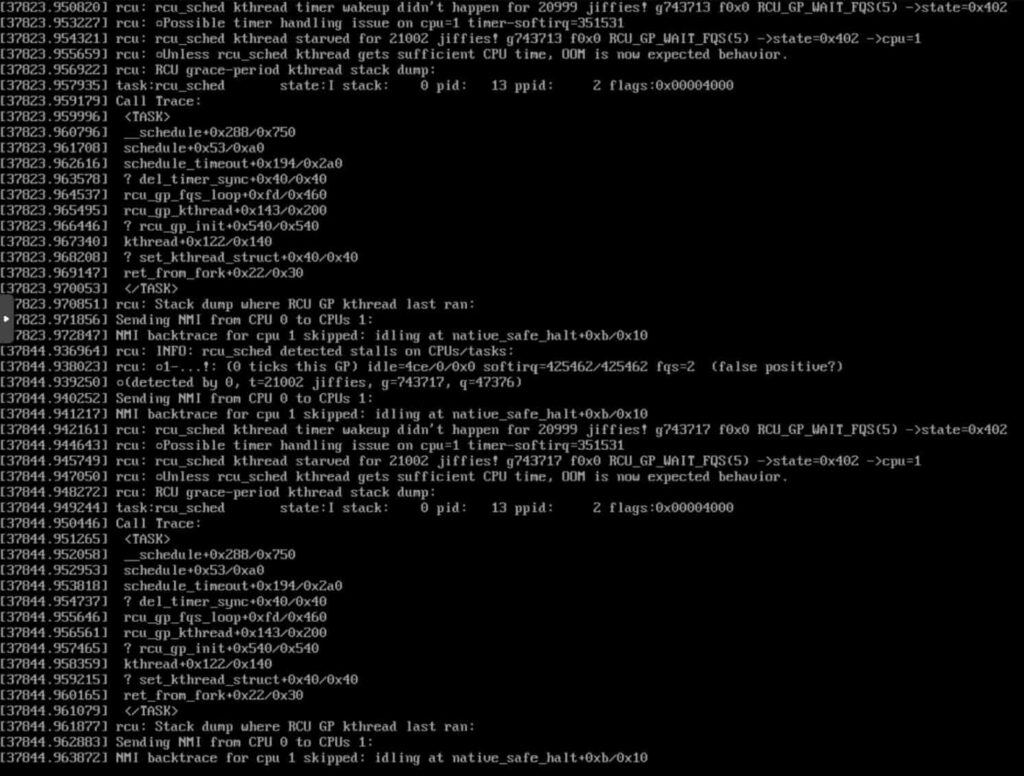
To tackle RCU_SCHED stalls, we need to take proactive steps. This means we should be ready to deal with problems before they happen.
We can do this by making sure our system settings are right. Also, we can adjust how tasks are scheduled to make things run smoother.
It’s like fixing a road before it gets too bumpy. Doing these things can prevent stalls from slowing down our system and keep things running smoothly.
Read: CPU Userbenchmark Bias – Investigate CPU Test Equality!
Optimizing Rcu Scheduler
- Fine-tuning Configuration: Adjusting kernel configuration options related to RCU scheduling for optimal performance.
- Utilizing RCU Variants: Exploring alternative RCU variants to improve scalability and performance in specific scenarios.
- Dynamic load balancing: Implementing dynamic load balancing mechanisms to distribute CPU load evenly and reduce stalls.
- Minimizing Lock Contention: Optimizing locking strategies to minimize Contention and improve system efficiency.
- Reducing Synchronization Overheads: Streamlining synchronization mechanisms to reduce overheads and enhance RCU scheduler performance.
- Analyzing Performance Metrics: Monitoring performance metrics to identify areas for optimization and measure the impact of changes.
- Benchmarking and Testing: Conducting benchmarking and testing to assess the effectiveness of optimization efforts and identify any regressions.
- Continuous Monitoring and Adjustment: Monitor system behavior and adjust optimization strategies to maintain peak performance.
- Documentation and Best Practices: Documenting optimization techniques and best practices to facilitate knowledge sharing and collaboration among developers.
- Collaborative Development: Engaging in collaborative development efforts to share insights and innovations for further enhancing RCU scheduler optimization.
Using RCU’s CPU Stall Detector
Utilize RCU’s CPU stall detector to identify CPU stalls within the kernel efficiently. This feature helps diagnose and address performance issues promptly, enhancing system reliability and responsiveness.
What Causes RCU CPU Stall Warnings?
RCU CPU stall warnings can be triggered by heavy system load, resource contention, inefficient synchronization mechanisms, or long-running tasks monopolizing CPU resources, leading to latency and performance degradation.
Fine-Tuning the RCU CPU Stall Detector
Tune the RCU CPU stall detector by adjusting parameters like detection thresholds and sampling intervals. This optimization ensures accurate detection of stalls, enabling timely intervention to maintain system performance and responsiveness.
Read: Not Enough CPU for Conversion Of This Item – Ultimate Guide!
Interpreting RCU’s CPU Stall-Detector “Splats”
Understanding RCU’s CPU stall-detector’ splats’ involves interpreting the logged data points representing instances of CPU stalls. Analyzing these splats provides insights into stalls’ frequency, duration, and potential causes, aiding in effective troubleshooting and optimization.
Multiple Warnings From One Stall
Multiple warnings from one stall indicate recurring CPU delays within RCU, suggesting persistent issues requiring thorough investigation and targeted resolution to optimize system performance.
Stall Warnings for Expedited Grace Periods
Stall warnings for expedited grace periods signal instances where RCU’s grace period is accelerated due to detected CPU stalls, ensuring timely completion of critical operations and maintaining system responsiveness.
Rcu_sched detected stall on CPU
Rcu_sched detected stall on CPU highlights a stall detected by RCU’s scheduling component. This indicates potential delays in task execution and necessitates prompt analysis and mitigation for optimal system operation.
What might cause a single “rcu_sched detected stall on CPU” warning in syslog?
A single ‘rcu_sched detected stall on CPU’ warning in syslog may arise from CPU contention, long-running tasks, or synchronization issues within RCU, necessitating investigation for optimal system performance.
“Rcu_sched detected stalls on CPUs/tasks” – jiffies – ESXi Ubuntu 16 FileServer Guest
Rcu_sched detected stalls on CPUs/tasks, measured in jiffies, indicating delays in task scheduling within an ESXi Ubuntu 16 FileServer Guest. These could potentially affect system responsiveness and require performance optimization.
Read: Corespotlightd High CPU – Boost Core Spotlight Performance!
Rcu_sched self-detected stall on CPU + watchdog: BUG: soft lockup – CPU#3 stuck for 22s
Rcu_sched self-detected stall on CPU + watchdog: BUG: soft lockup – CPU#3 stuck for 22s signifies a detected CPU stall by RCU’s watchdog mechanism, indicating prolonged task execution delays requiring immediate attention for system stability.
What does ‘self-detected stall on CPU’ syslog message denote on Ubuntu 16?
The ‘self-detected stall on CPU’ Syslog message on Ubuntu 16 denotes RCU’s self-diagnosis of a CPU stall, suggesting potential performance issues requiring analysis and resolution for optimal system operation.
kernel: INFO: rcu_sched self-detected stall on CPU on Allwinner H3, Ubuntu 16.04.6 LTS 4.14.52
Kernel: INFO: rcu_sched self-detected stall on CPU on Allwinner H3, Ubuntu 16.04.6 LTS 4.14.52 signifies RCU detecting a CPU stall on a specific hardware configuration and OS version, indicating potential performance issues.
Errors – Not Booting: RCU_SCHED SELF-DETECTED STALL ON CPU
Errors – Not booting: RCU_SCHED SELF-DETECTED STALL ON CPU suggests boot failure due to detected CPU stalls by RCU, necessitating troubleshooting for successful system startup.
Read: Integrated Graphics CPU Or Not – Comprehensive Guide – 2024!
RCU CPU Stall Warnings
RCU CPU stall warnings indicate occurrences of CPU stalls detected by RCU, which can impact system performance and stability, requiring analysis and mitigation for optimal operation.
Rcu_sched detected stalls on VirtualBox #1705
Rcu_sched detected stalls on VirtualBox #1705 highlights detected CPU stalls within a VirtualBox environment, which affect guest OS performance and require optimization for smoother operation.
Proxmox 8.1 – kernel 6.5.11-4 – rcu_sched stall CPU
Proxmox 8.1 – kernel 6.5.11-4 – rcu_sched stall CPU denotes RCU detecting stalls on Proxmox 8.1 with kernel version 6.5.11-4, signalling potential performance issues requiring investigation and resolution.
Do I need to worry about CPU stall warnings?
Do I need to worry about CPU stall warnings? CPU stall warnings should be investigated to identify underlying causes and mitigate performance impacts, ensuring optimal system operation and stability.
Read: Does CPU Affect Download Speed – Increase Download Speed!
Rcu_sched self-detected stall on CPU VMware
Rcu_sched self-detected stall on CPU VMware indicates RCU detecting CPU stalls in a VMware environment, necessitating analysis and optimization for improved virtual machine performance.
Rcu_sched self detected stall on CPU centos
Rcu_sched self-detected stall on CPU centos signals RCU detecting CPU stalls in a CentOS environment, requiring investigation and resolution to ensure smooth system operation.
Unraid Rcu info Rcu_preempt self-detected stall on CPU
Unraid Rcu info Rcu_preempt self-detected stall on CPU suggests RCU detecting preemptable CPU stalls in an Unraid environment, requiring analysis and optimization for enhanced system performance.
Rcu_sched detected stalls on cpus/tasks Xilinx
Rcu_sched detected stalls on CPUs/tasks. Xilinx indicates that RCU detects stalls in Xilinx environments, potentially impacting system performance and requiring investigation and optimization for smoother operation.
Rcu_sched high CPU usage
Rcu_sched high CPU usage suggests elevated CPU utilization attributed to RCU scheduling, requiring optimization measures to mitigate performance impact and ensure efficient system operation.
Rcu_preempt self-detected stall on CPU home assistant
Rcu_preempt self-detected stall on CPU Home Assistant denotes RCU detecting self-diagnosed CPU stalls in a Home Assistant environment, necessitating analysis and resolution for improved system performance.
Rcu_preempt detected stalls on cpus/tasks
Rcu_preempt detected stalls on cpus/tasks indicate preemptable CPU stalls detected by RCU, potentially affecting task scheduling and system responsiveness, requiring investigation and optimization for optimal operation.
Read: CPU Core Ratio Sync All Cores Or Auto – System Optimization!
Conclusion
Final Words,
Optimizing the RCU scheduler is essential for maintaining system performance and responsiveness. By fine-tuning configuration, minimizing Contention, and continuously monitoring metrics, we can ensure smooth operation and mitigate the risk of RCU_sched self-detected stalls.
Related Questions
1. What causes RCU_SCHED stalls?
RCU_SCHED stalls can arise due to various factors, including resource contention, kernel configuration issues, and suboptimal scheduling parameters.
2. How can I monitor RCU_SCHED performance?
Monitoring tools such as perf, kernel debuggers, and system monitoring utilities offer insights into RCU_SCHED behavior and performance metrics.
3. Are there any known mitigation techniques for RCU_SCHED stalls?
Mitigation strategies encompass kernel optimizations, scheduling parameter adjustments, and workload-specific tuning to alleviate the impact of stalls.
4. What role does community collaboration play in addressing RCU_SCHED stalls?
Community-driven efforts contribute to the ongoing refinement of RCU and related components, fostering innovation and resilience in Linux kernel development.
5. What are the long-term implications of RCU_SCHED stalls on system performance?
Addressing RCU_SCHED stalls is essential for ensuring sustained system reliability, scalability, and responsiveness, particularly in high-demand computing environments.
6. What causes a RCU stall?
A RCU stall can be caused by factors like heavy system load, resource contention, or inefficient synchronization mechanisms, leading to delays in Read-Copy-Update operations within the kernel.
7. What causes CPU stalls?
CPU stalls can result from various factors such as cache misses, pipeline bubbles, or waiting for memory access, inhibiting the processor from executing instructions efficiently.
8. How to debug RCU stalls?
Debugging RCU stalls involves using kernel tracing tools like ftrace or perf to identify bottlenecks, analyzing system logs, and optimizing critical sections to enhance performance and responsiveness.
9. What is Rcu_sched in Linux?
Rcu_sched in Linux is a component implementing Read-Copy-Update for task scheduling purposes, ensuring efficient and scalable concurrent data structure manipulation within the kernel.
10. What is RCU CPU?
RCU CPU refers to the utilization of Read-Copy-Update synchronization mechanism within the kernel, facilitating concurrent read-side operations while efficiently handling updates to shared data structures.
Read More:
- CPU C-States On Or Off Gaming – Unlock Peak Performance!
- CPU Usage Drops When I Open Task Manager – Ultimate Guide!
- Not Enough CPU for Conversion Of This Item – Ultimate Guide!

Hi everyone, Johns Jack here, your approachable tech aficionado! I’m passionate about CPUs and thrive on keeping up with the newest tech developments. Join me as we delve into the dynamic realm of technology! Visit: Techy Impacts